Table of Contents
Guess which row features the most convicted pedophiles in the US!
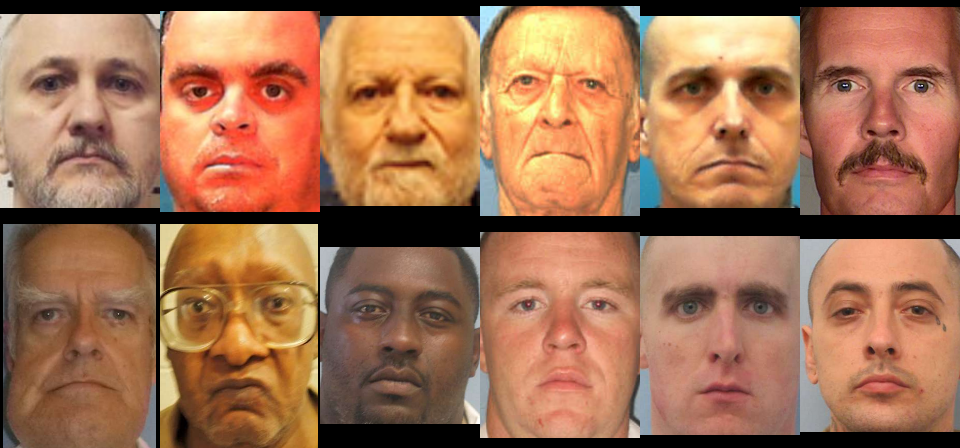
TL;DR
- Rich dataset of 1.2 million criminals.
- 160k+ faces analyzed for CNN.
- Convicted pedophiles are most likely to be older, white, overweight men.
- Our model achieved 69% accuracy in classifying pedophiles from facial features alone.
Introduction
When ImageNet debuted in 2009, it revolutionized computer vision with its dataset of over a million images spanning more than 1,000 object categories. The first ImageNet competition in 2010 saw a winning accuracy of just 52.9%, but everything changed two years later when AlexNet achieved a breakthrough 63.3% accuracy—outperforming the runner-up by a staggering 10%.
Although modest by today’s standards, this achievement ignited the neural network “deep learning” revolution, transforming neural networks from academic curiosities into the foundation of modern AI. In the following years, innovations accelerated rapidly. By 2017, models surpassed 90% accuracy on the 1,000-class challenge, with top-5 accuracy exceeding 95%—better than human performance.
Remarkably, 2017 was only seven years ago, yet in the rapidly evolving field of machine learning, it feels like ancient history. Today’s models vastly outperform anything from that era.
To the point.
Modern AI research has largely pivoted toward developing “everything” models—systems that understand and generate all forms of media (audio, video, text, images) and can solve problems across countless domains. The pursuit of artificial general intelligence (AGI) dominates the field.
Few serious ML scientists now focus on narrow, specific tasks. This is partly because the oxygen has been sucked out of the room with focus on LLMs. However, it’s also because there’s nothing novel in doing the next run of the mill CNN anymore. Predicting attributes such as age, gender, race, body mass index (BMI), facial expressions have all been solved. Or if they haven’t been solved, it’s only because a dataset hasn’t been assembled to do so. Lastly, the remaining low hanging fruit could be considered controversial - predicting political beliefs, religiosity, personality or criminality.
However, some have still pursued this line of research in the 2020s. Hashemi and Hall (2020) published research demonstrating that convolutional neural networks could distinguish between “criminal” and “non-criminal” facial images with a reported accuracy of 97% on their test set. While this paper was later retracted for ethical concerns rather than methodological flaws, it highlighted the potential for facial analysis to extend beyond physical attributes into behavior prediction. Similarly, Kosinski (2021) demonstrated that facial recognition technology could predict political orientation from naturalistic facial images with 72% accuracy, significantly outperforming human judges who achieved only 55% accuracy. These models maintained substantial predictive power even when controlling for demographic variables such as age, gender, and ethnicity.
We’ll continue that trend: predicting pedophilic behavior based solely on facial features, bringing levity to a serious criminal issue.
Dataset
Criminal Mugshots and Offenses Collection
Without readily available public datasets for this task, I turned to my existing database of approximately 2 million mugshots collected from previous scraping projects. This data comes directly from various state Department of Corrections websites across the US.
The dataset contains multiple mugshots for some individuals, and not all entries include offense information. After cleaning and preprocessing, I retained 1.2 million unique criminal mugshots with documented offenses, allowing me to differentiate between pedophiles and other criminals.
Preliminary Linear Modeling
The full dataset often includes demographic and physical attributes: race, gender, hair color, eye color, BMI, and more. To begin my investigation, I ran a logistic regression model to identify which basic characteristics correlate with pedophilia.
For reference in interpreting the results:
- Race comparisons use White as the baseline
- Hair color comparisons use Black as the baseline
- Eye color comparisons use Brown as the baseline
The p-values reveal that most characteristics show statistically significant correlations:
| Variable | Estimate | Std. Error | z value | Pr(>|z|) |
|---|---|---|---|---|
| (Intercept) | -4.365543 | 0.033882 | -128.840 | < 2e-16 *** |
| Race: Asian or Pacific Islander | -0.061732 | 0.056318 | -1.096 | 0.2730 |
| Race: Black | -0.713166 | 0.016731 | -42.625 | < 2e-16 *** |
| Race: Hispanic | -0.359594 | 0.014707 | -24.498 | < 2e-16 *** |
| Race: Native American | -0.877637 | 0.035972 | -24.398 | < 2e-16 *** |
| Gender: Male | 2.492670 | 0.033871 | 73.594 | < 2e-16 *** |
| Hair Colour: Bald | 0.490651 | 0.044792 | 10.954 | < 2e-16 *** |
| Hair Colour: Blond | -0.166804 | 0.023397 | -7.129 | 1.01e-12 *** |
| Hair Colour: Brown | -0.027019 | 0.021634 | -1.249 | 0.2115 |
| Hair Colour: Gray | 0.721222 | 0.018989 | 37.980 | < 2e-16 *** |
| Hair Colour: Other | 0.078159 | 0.018989 | 4.116 | 3.85e-05 *** |
| Hair Colour: Red | 0.019859 | 0.040568 | 0.490 | 0.6245 |
| Eye Colour: Black | 0.079842 | 0.045133 | 1.769 | 0.0769 . |
| Eye Colour: Blue | 0.007838 | 0.037538 | 0.209 | 0.8343 |
| Eye Colour: Gray | 0.368979 | 0.088534 | 4.168 | 3.08e-05 *** |
| Eye Colour: Green | -0.179199 | 0.022199 | -8.072 | 6.90e-16 *** |
| Eye Colour: Hazel | -0.012198 | 0.019949 | -0.765 | 0.4444 |
| BMI | 0.199056 | 0.004355 | 45.709 | < 2e-16 *** |
Significance codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ’ ’ 1
For easier interpretation, here are the odds ratios for statistically significant attributes:
| Variable | Odds Ratio |
|---|---|
| Gender: Male | 10.66150373 |
| Hair Colour: Gray | 2.05694459 |
| Hair Colour: Bald | 1.63337870 |
| Hair Colour: Other | 1.44625657 |
| BMI | 1.22024993 |
| Eye Colour: Black | 1.08311545 |
| Hair Colour: Red | 1.02005784 |
| Eye Colour: Gray | 1.03000074 |
| Eye Colour: Hazel | 0.98787646 |
| Hair Colour: Brown | 0.97332489 |
| Race: Asian or Pacific Islander | 0.94013521 |
| Hair Colour: Blond | 0.84636543 |
| Eye Colour: Green | 0.83621333 |
| Race: Hispanic | 0.67595334 |
| Race: Black | 0.49009014 |
| Race: Native American | 0.41576433 |
| (Intercept) | 0.01070758 |
Translating these odds ratios into plain English, our data suggests that convicted pedophiles tend to be:
- Male (over 10 times more likely than females)
- Older (indicated by gray hair, baldness, and gray eyes)
- Overweight (higher BMI correlates with increased likelihood)
- White (all other racial groups show lower odds ratios)
While this linear model’s overall predictive accuracy barely outperformed random guessing, our enormous sample size allowed us to identify statistically significant demographic patterns. The consistent associations with age markers (gray hair, baldness, gray eyes) lend credibility to these findings. Personally, I think these patterns align with common stereotypes about pedophile offenders.
Now, let’s move to our more sophisticated approach using convolutional neural networks.
PedoAI CNN Methodology
Creating this AI involved four key steps:
1. Classifying Pedophilia-Related Offenses with LLMs
Criminal offenses appear in widely varying formats across our dataset:
- “Poss W Purp Del Cont Sub LSD => 80 DU < 160 DU”
- “Theft of leased/rented property =>,000”
- “FACILITATION MARIJUANA VIOLATION”
With approximately 33,000 distinct offense descriptions among 1.2 million criminals, manual classification would be prohibitively time-consuming. I leveraged Gemini Flash 2.0 to identify pedophilia-related offenses, completing the task for about $1.
2. Extracting and Standardizing Facial Images
For our model to focus purely on facial features—not clothing, background, or other variables—we needed to isolate and standardize faces from the mugshots. This process involved:
-
Using multiple face detection models from the DeepFace library (MTCNN, YOLOv8, RetinaFace) with fallback options if primary detection failed
-
Resizing all extracted faces to 160 × 224 pixels while preserving aspect ratio using black padding
I determined these dimensions after analyzing 10,000 sample faces:
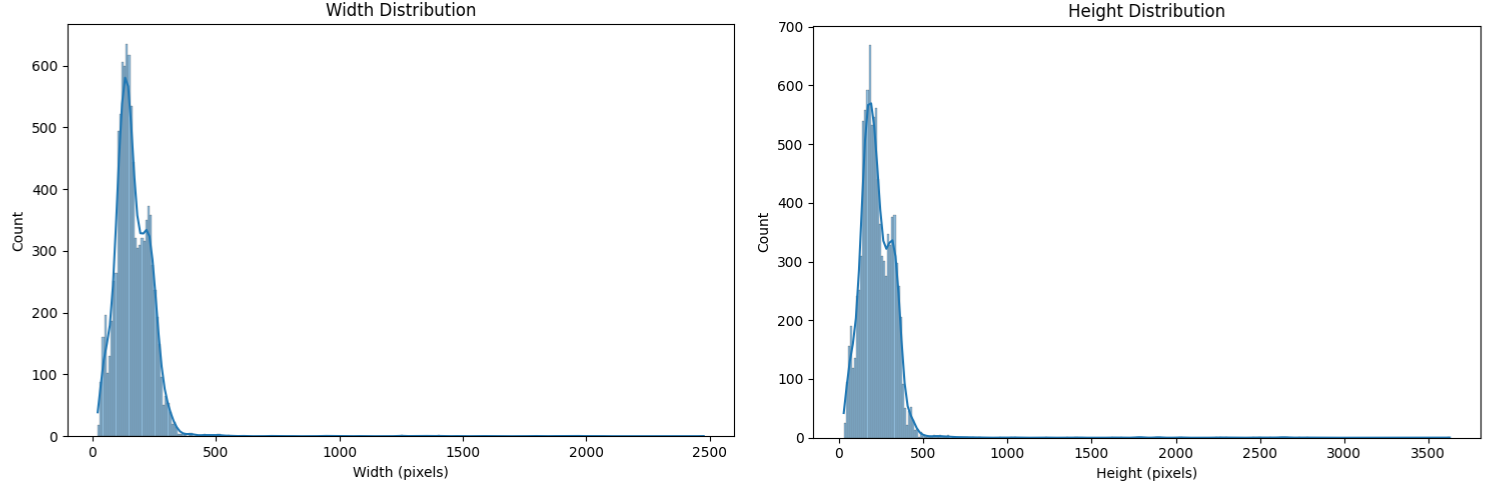
| Statistic | Width | Height |
|---|---|---|
| Mean | 167.30 | 228.74 |
| Median | 153.00 | 211.00 |
| Std | 101.03 | 139.58 |
The 160 × 224 pixel dimensions were chosen because:
- Both numbers are divisible by 32 (computationally efficient)
- The width-to-height ratio (1.4) closely matches the natural proportions found in our dataset (1.38)
- 224 pixels is a standard height for facial recognition models
Here’s a visual example of our extraction process:

3. Data Selection for Training
While our 1.2 million image dataset provides robust training material, training on the full set would require excessive computational resources, especially during hyperparameter optimization (which requires multiple training runs).
I struck a balance by using 100,000 pedophile images and 100,000 non-pedophile images for training, with separate validation and test sets of approximately 20,000 images each.
4. Training with Progressive Scaling
To understand how model performance scales with dataset size, I conducted 50 hyperparameter tuning runs at each of the following sample sizes: 5k, 10k, 20k, 40k, 80k, and the full 160k faces. This required training a total of 300 distinct models while maintaining consistent validation and test sets.
Results
Rather than presenting dry performance tables, I decided to test our model in a more engaging way. I connected PedoAI to a browser and let it play pedoguessr, a game where players guess which of two faces belongs to a convicted pedophile.
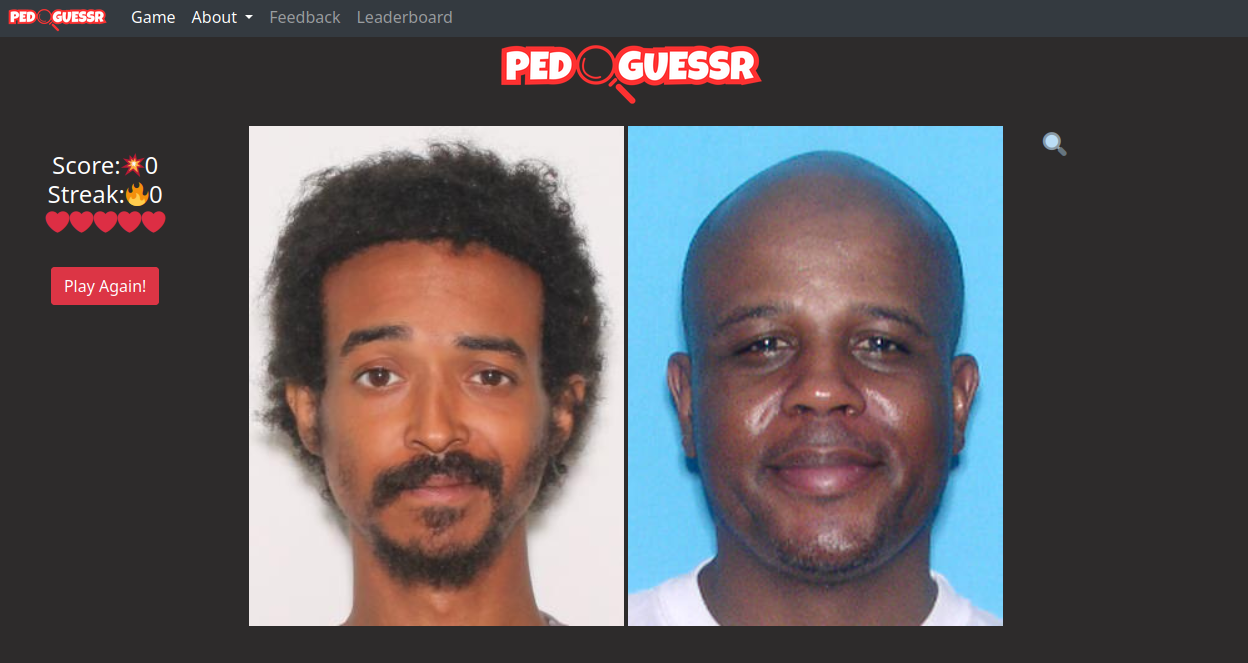
How did it perform? Unfortunately, not well in this context. Since my model’s accuracy isn’t exceptionally high, performance in this game largely came down to luck. Random guessing can achieve scores of 20-30, so I needed many trials to properly evaluate the AI’s capabilities.
Taking advantage of a game exploit that allowed indefinite play (earning the username “Filthy Cheater!” the #1 spot on the leaderboard), I let the AI complete 303 rounds. The results were disappointing: wrong in 160 out of 303 rounds—worse than random guessing.
Even more concerning, the model’s confidence levels didn’t correlate with its accuracy. In theory, when the AI sees a bigger difference in predicted probabilities between two images (e.g., 1% vs. 75% likelihood of being a pedophile), it should be more likely to get the answer right than when the probabilities are close (51% vs. 52%). However, statistical analysis showed no significant relationship:
> glm(is_wrong ~ diff, data = testing, family = binomial()) %>%
+ broom::tidy()
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 0.242 0.169 1.43 0.154
2 diff -0.00513 0.00493 -1.04 0.298 <--- Confidence does not predict anything
Despite these disappointing game results, the model performed much better on our controlled test set. On a sample of 20,000 faces the model never saw during training, it achieved 68.88% accuracy—significantly better than random chance:
| Predicted: Not Pedo | Predicted: Pedo | |
|---|---|---|
| Actual: Not Pedo | 7,615 | 2,868 |
| Actual: Pedo | 3,660 | 6,832 |
We also observed clear scaling benefits with larger training datasets:
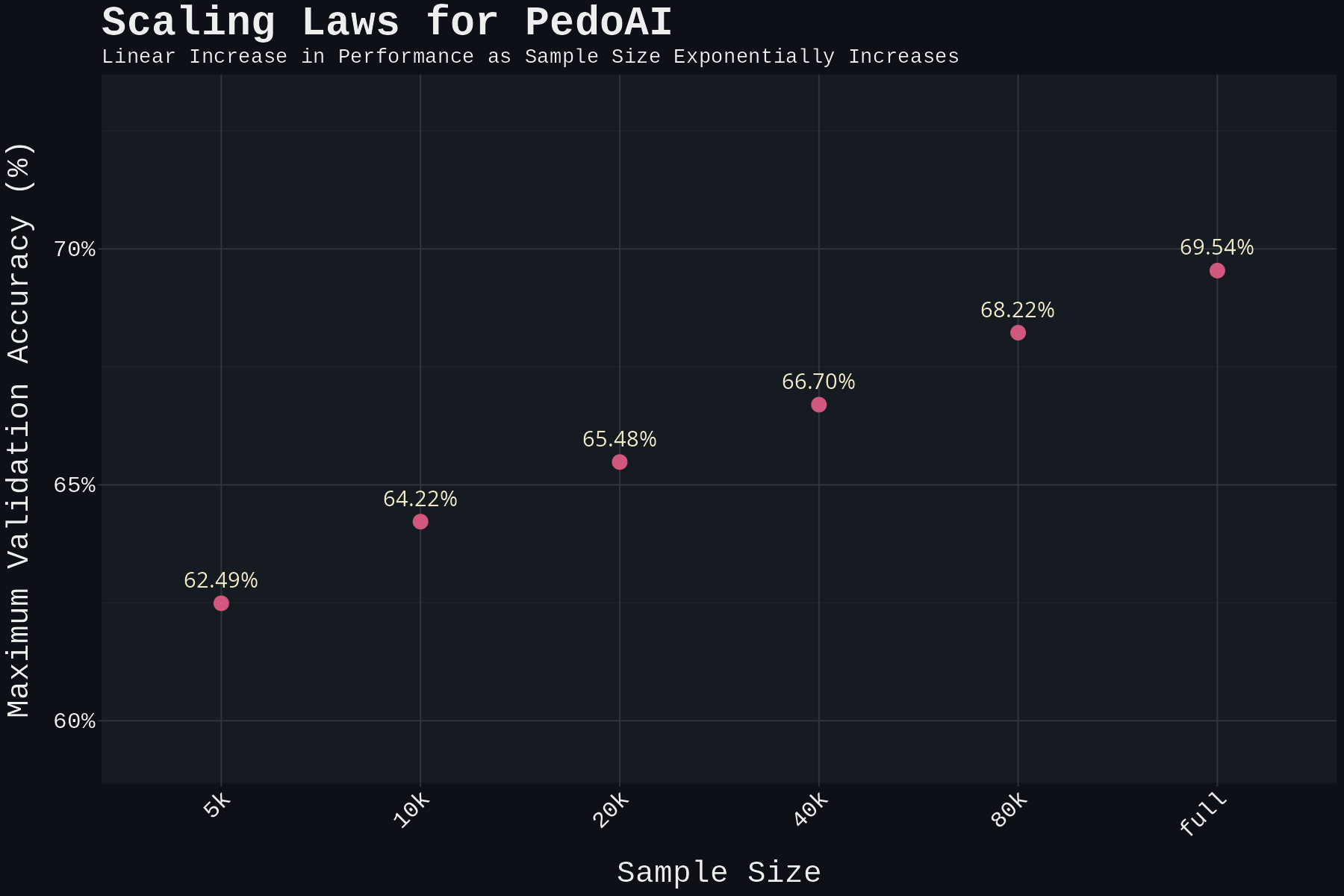
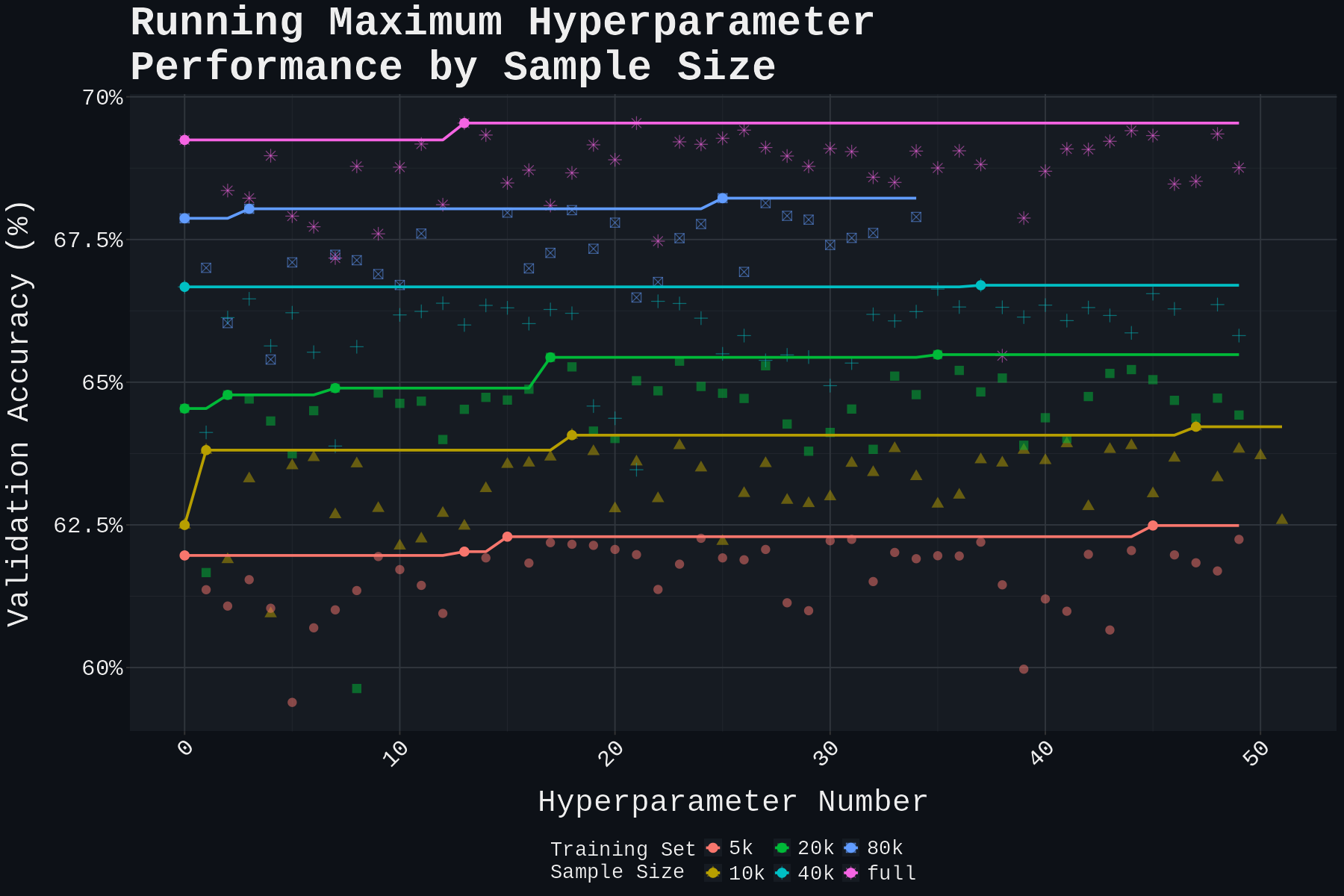
Why did our model struggle with the pedoguessr game despite its reasonable performance on our test set? The discrepancy likely stems from different labeling criteria. The game creator may have used different standards to classify pedophiles, perhaps focusing on different offense types or severity levels than those in our training data. This highlights a key limitation: while our model can predict better than random chance in controlled settings, it lacks broad generalizability to other contexts.
Conclusions
The results of this study present a complex picture of AI’s ability to predict pedophilic tendencies from facial features. While our model achieved nearly 69% accuracy on our test dataset, several important limitations must be acknowledged.
The study by Hashemi and Hall (2020) provides a cautionary tale about facial recognition models potentially overfitting to characteristics unrelated to facial morphology. Their model achieved a suspiciously high 97% accuracy while showing continual improvement as they added more convolutional layers, despite working with a relatively small dataset of just 10,000 images. This pattern of unending improvement with increased model complexity often signals overfitting rather than meaningful feature learning. In contrast, our approach used a much more modest architecture of only 4 layers despite having access to over 10 times their sample size. During our hyperparameter tuning across different sample sizes, we found that model performance did not universally improve with additional layers—instead, there was typically an optimal layer count beyond which performance plateaued or declined, suggesting a more honest learning process. Additionally, Hashemi and Hall’s study drew criminal and non-criminal images from fundamentally different sources, potentially allowing their algorithm to detect irrelevant environmental differences such as:
- Standardized lighting conditions
- Institutional clothing
- Controlled facial expressions
- Demographic characteristics typical of the university students who comprised their non-criminal sample.
Our approach mitigates these concerns by using mugshots from the same database for both pedophiles and non-pedophile criminals, significantly reducing the risk of systematic differences in image characteristics between our comparison groups.
Nevertheless, our model’s poor performance on the external “pedoguessr” dataset, where it performed worse than random chance, suggests limited generalizability beyond our specific dataset. As Kosinski (2021) noted in his work on political orientation prediction, even well-performing models can fail to transfer across contexts when they learn dataset-specific patterns rather than robust physiological markers.
The Bayesian prior issue presents another significant limitation. Our model was trained on a balanced dataset containing 50% pedophiles and 50% non-pedophile criminals. This equal distribution dramatically overrepresents the actual prevalence of pedophiles in the general population. In real-world applications, even a model with seemingly impressive accuracy metrics would generate an unacceptable number of false positives when applied to a population with a much lower base rate of the target condition. While this could be addressed through threshold adjustments, such tuning would inevitably reduce the model’s ability to correctly identify actual pedophiles (reduction in false positives leads to an increase in false negatives through this method).
Perhaps most fundamentally, we may be attempting to make distinctions between groups that are topologically close in feature space. Both groups in our study consist of individuals convicted of crimes - pedophilia representing one specific criminal category. The physiological and demographic similarities between different types of criminals likely create substantial overlap that makes clean classification inherently difficult. Unlike distinguishing between broader categories (such as political orientation, as demonstrated by Kosinski, 2021), differentiating between subtypes of criminals may require signals too subtle for current computer vision techniques to reliably detect.
This post highlights the significant gap between laboratory performance and real-world applicability of facial analysis for predicting complex behavioral traits. While our results show some statistical relationship between facial features and criminal pedophilic behavior, the limitations in generalizability, base rate considerations, and potential dataset artifacts suggest caution is warranted.
References
- Hashemi, M., & Hall, M. (2020). Criminal tendency detection from facial images and the gender bias effect. Journal of Big Data, 7(2), 1-16. https://doi.org/10.1186/s40537-019-0282-4
- Kosinski, M. (2021). Facial recognition technology can expose political orientation from naturalistic facial images. Scientific Reports, 11(100), 1-7. https://doi.org/10.1038/s41598-020-79310-1
AIs Makes us Stupid, Smart
Smart Extinction? Projecting the Future of Global Intelligence and Innovation
Machine-Learning