Supplementary Materials
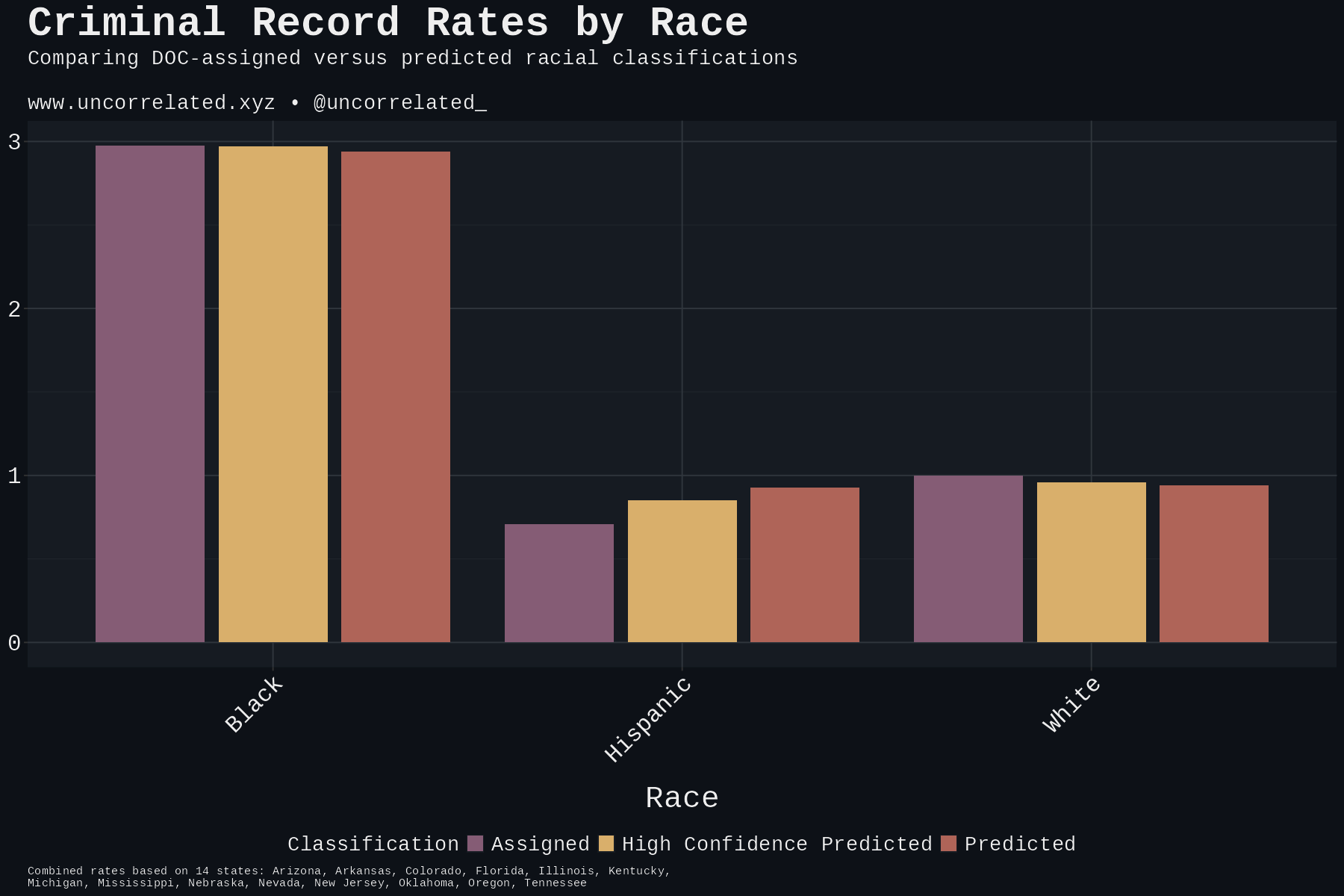
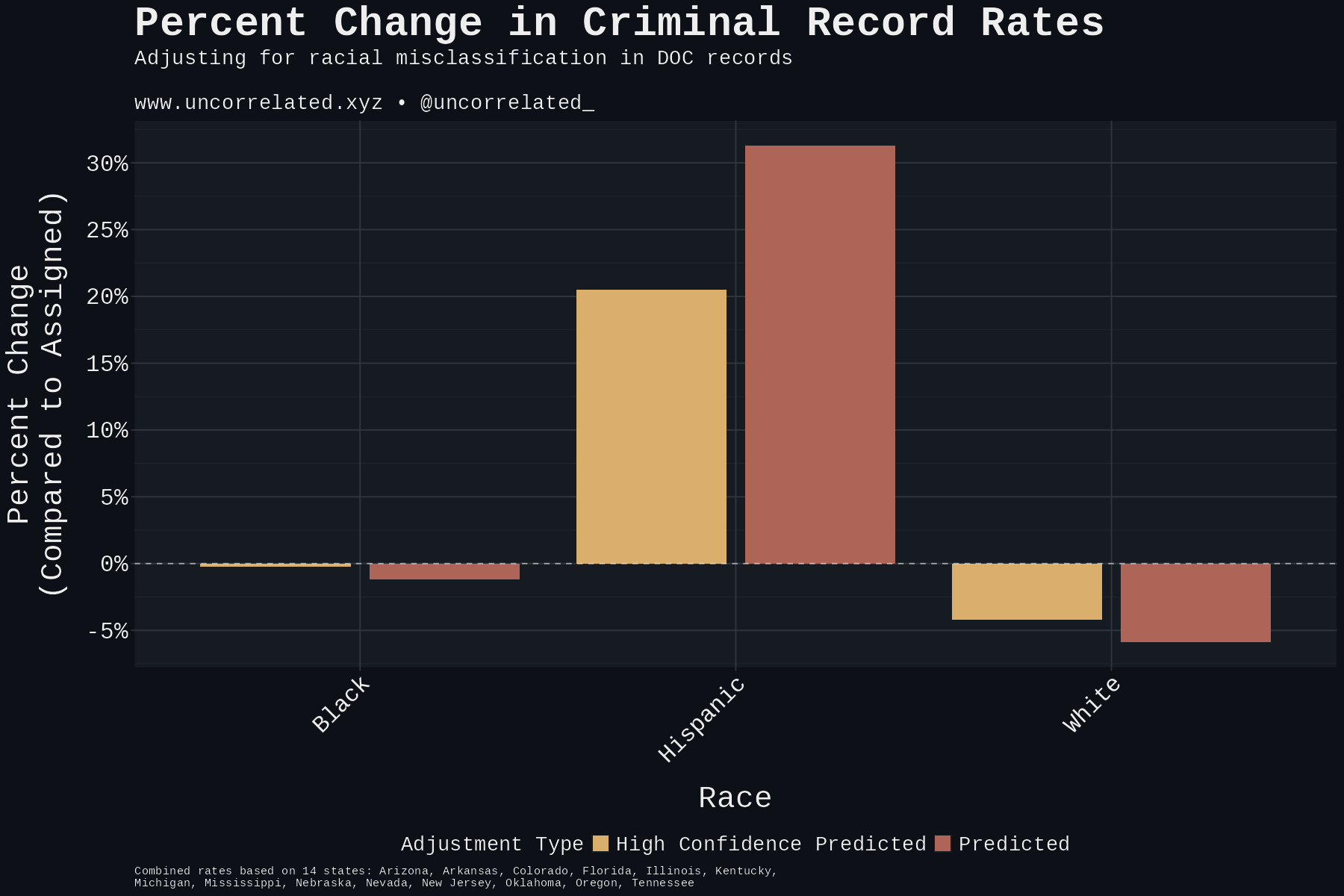
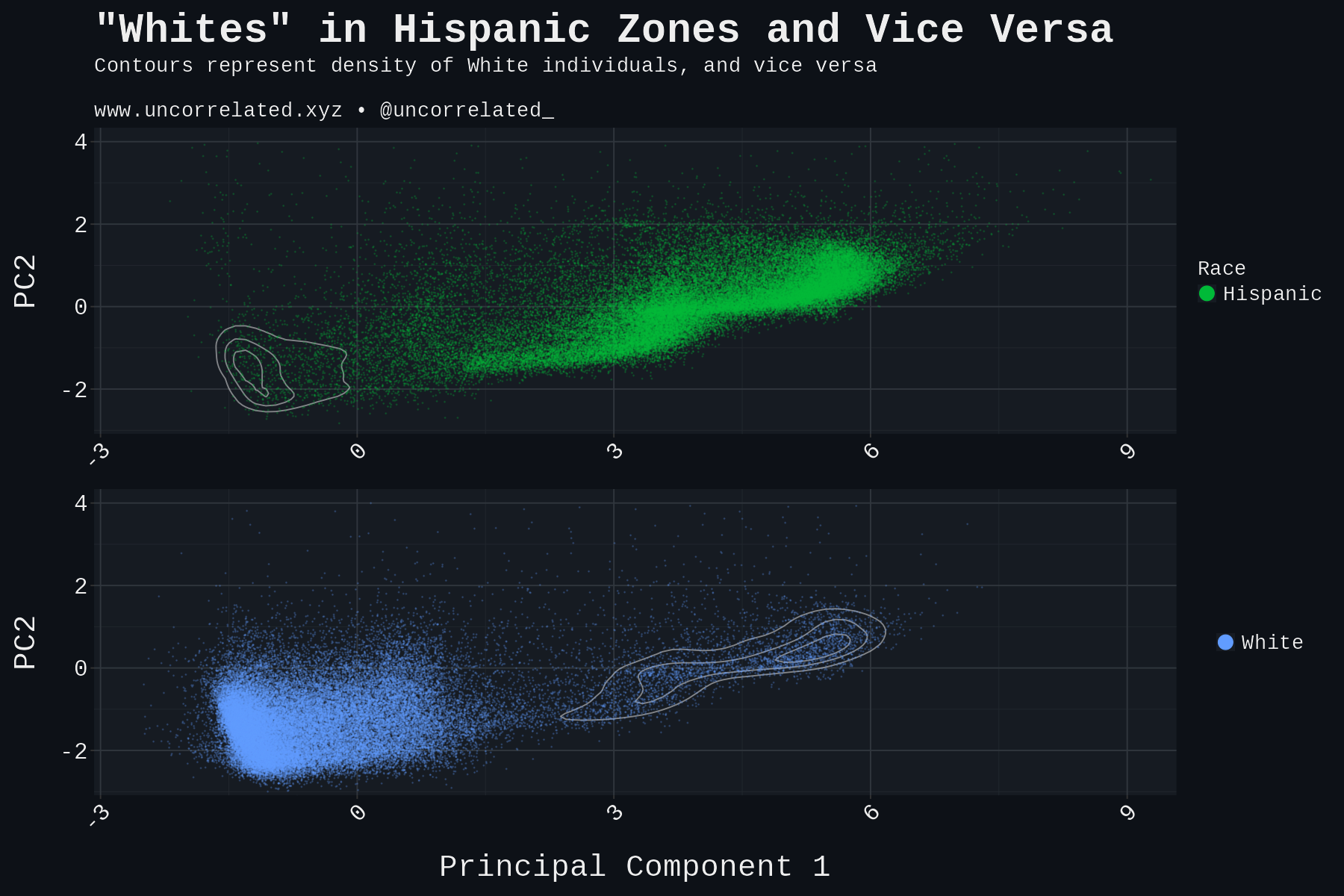
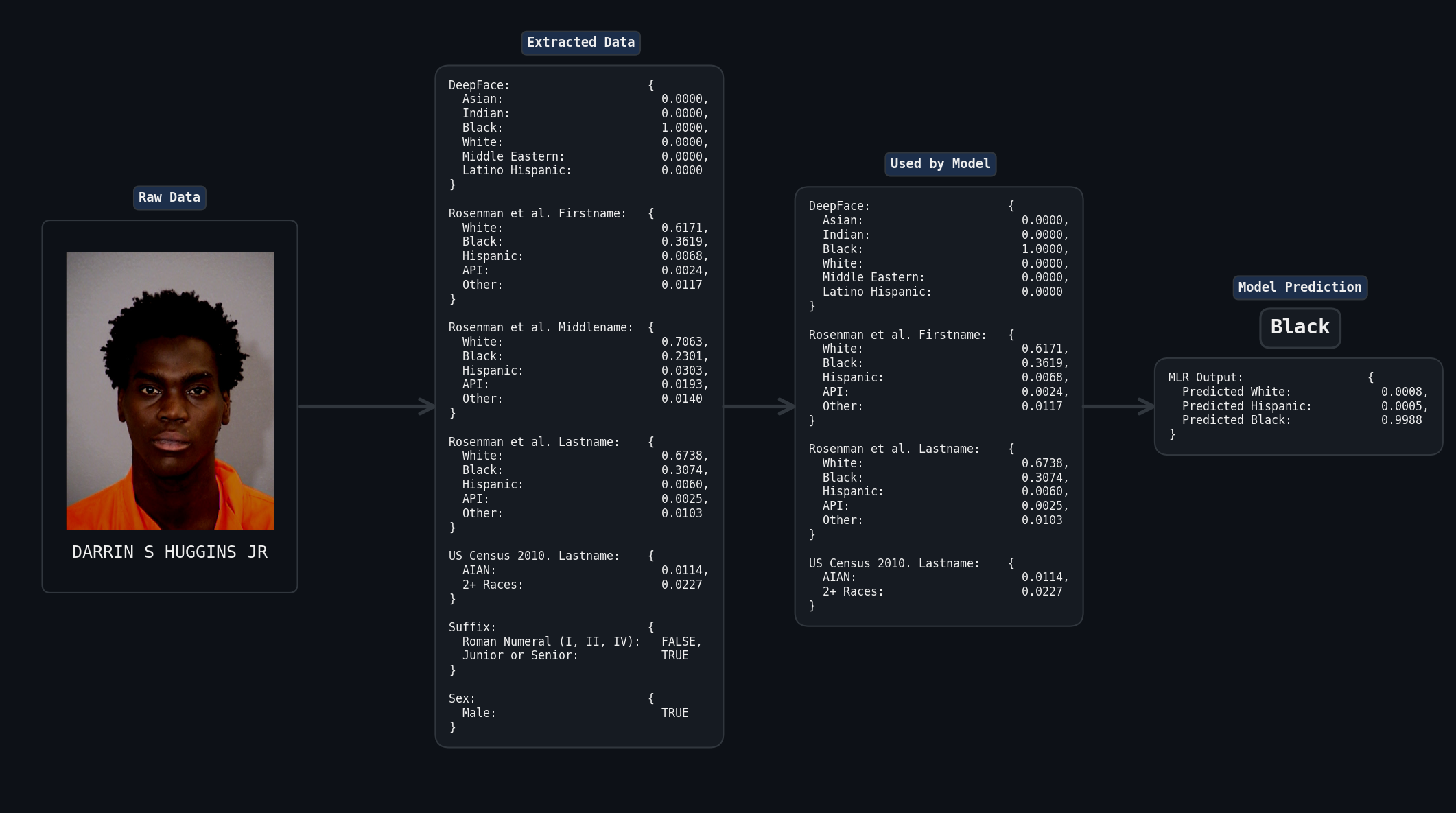
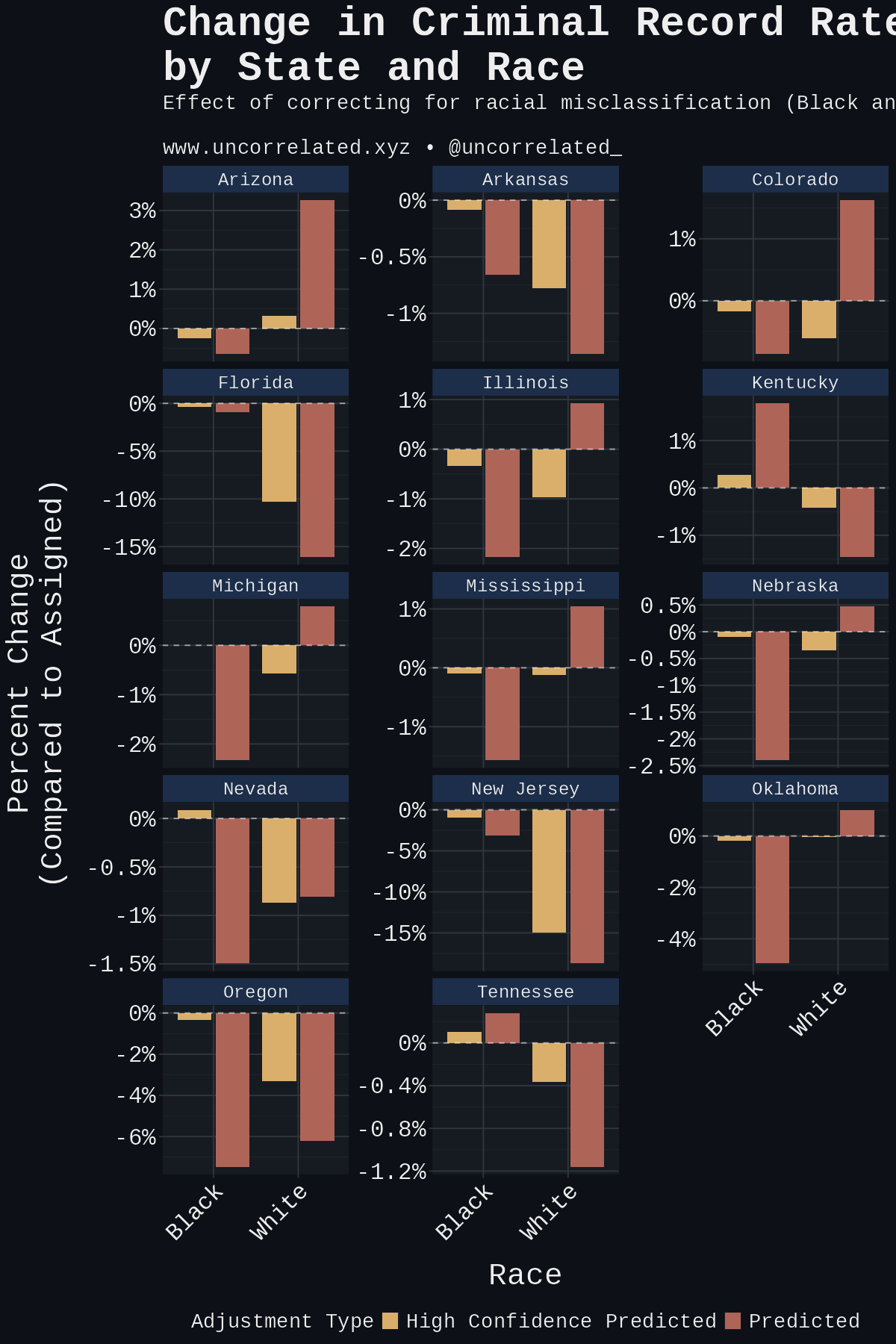
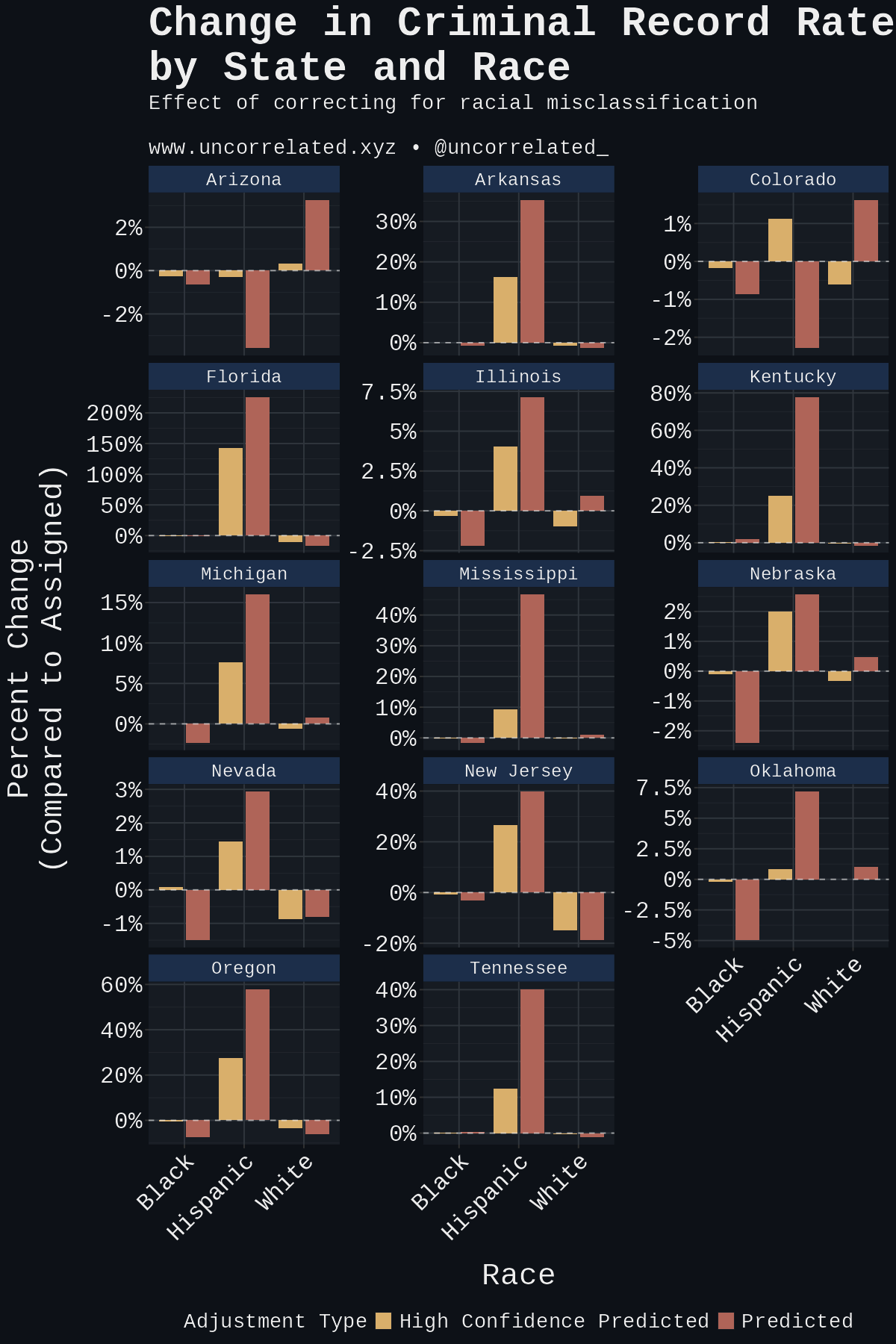
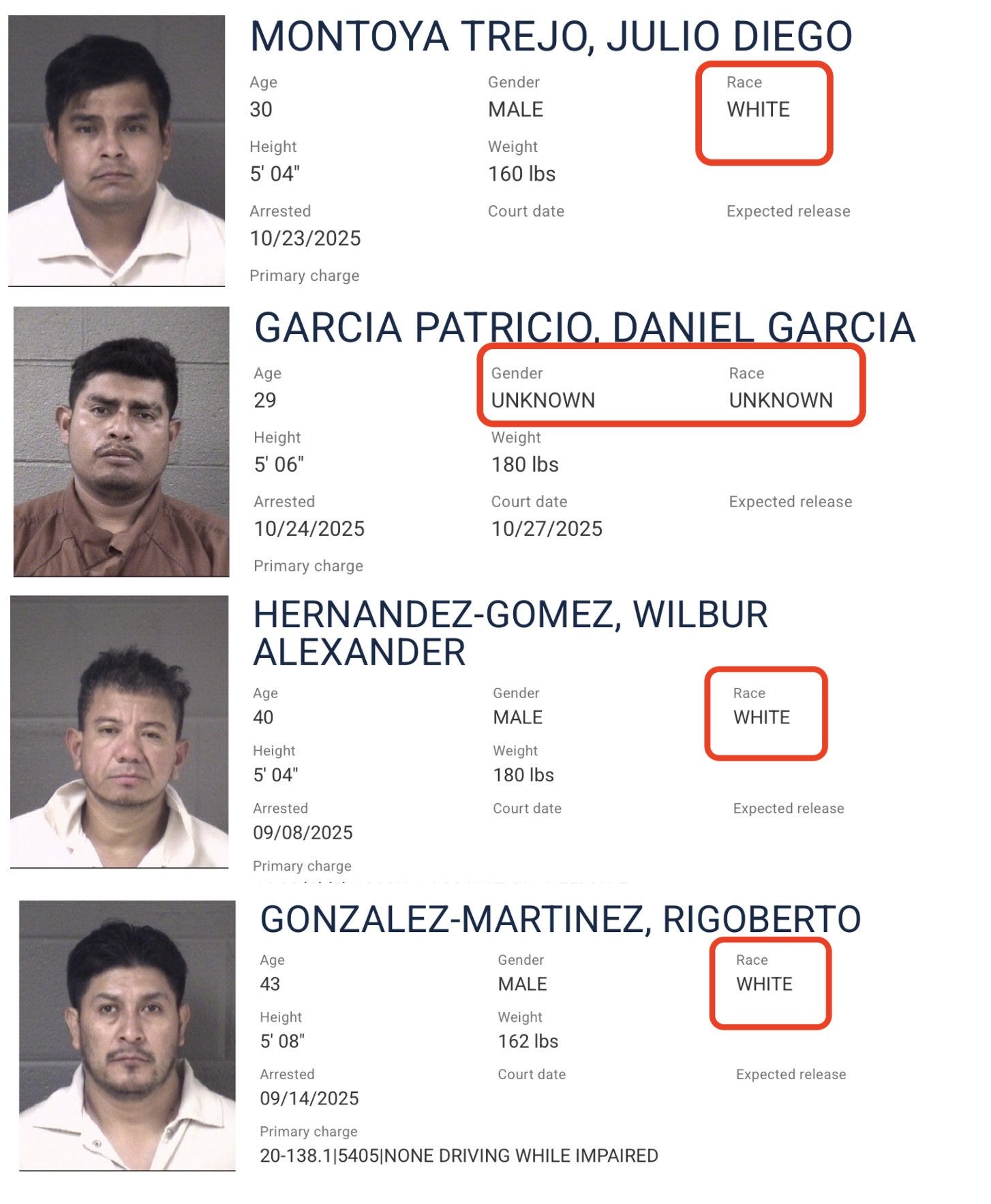
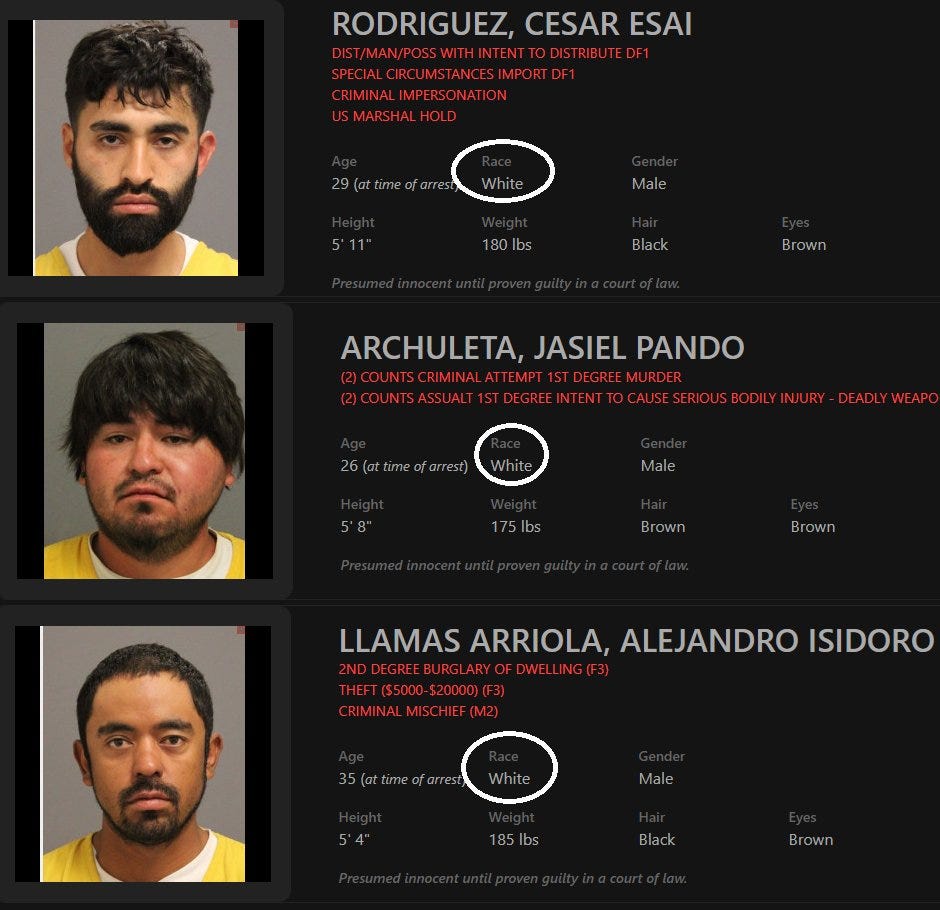
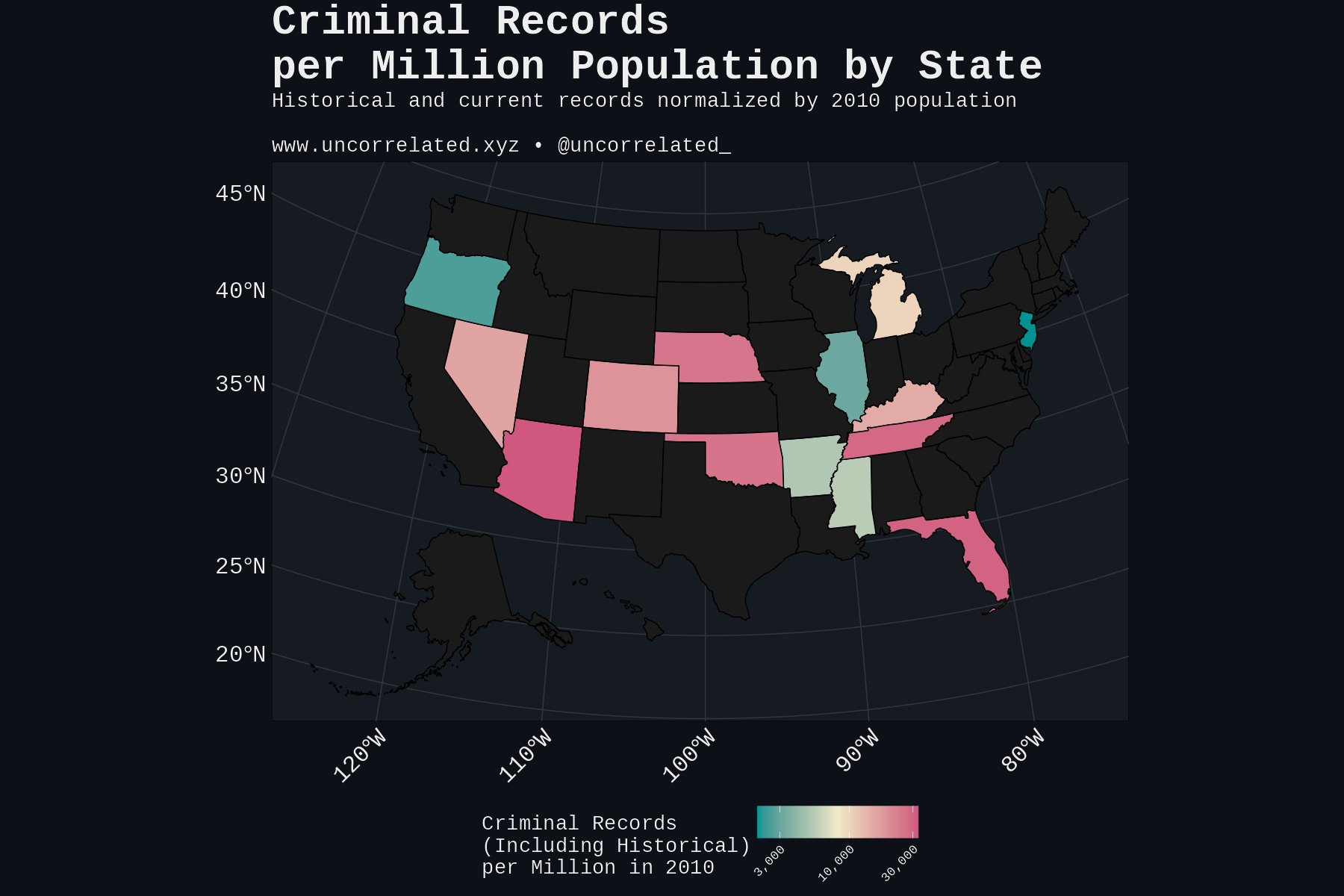
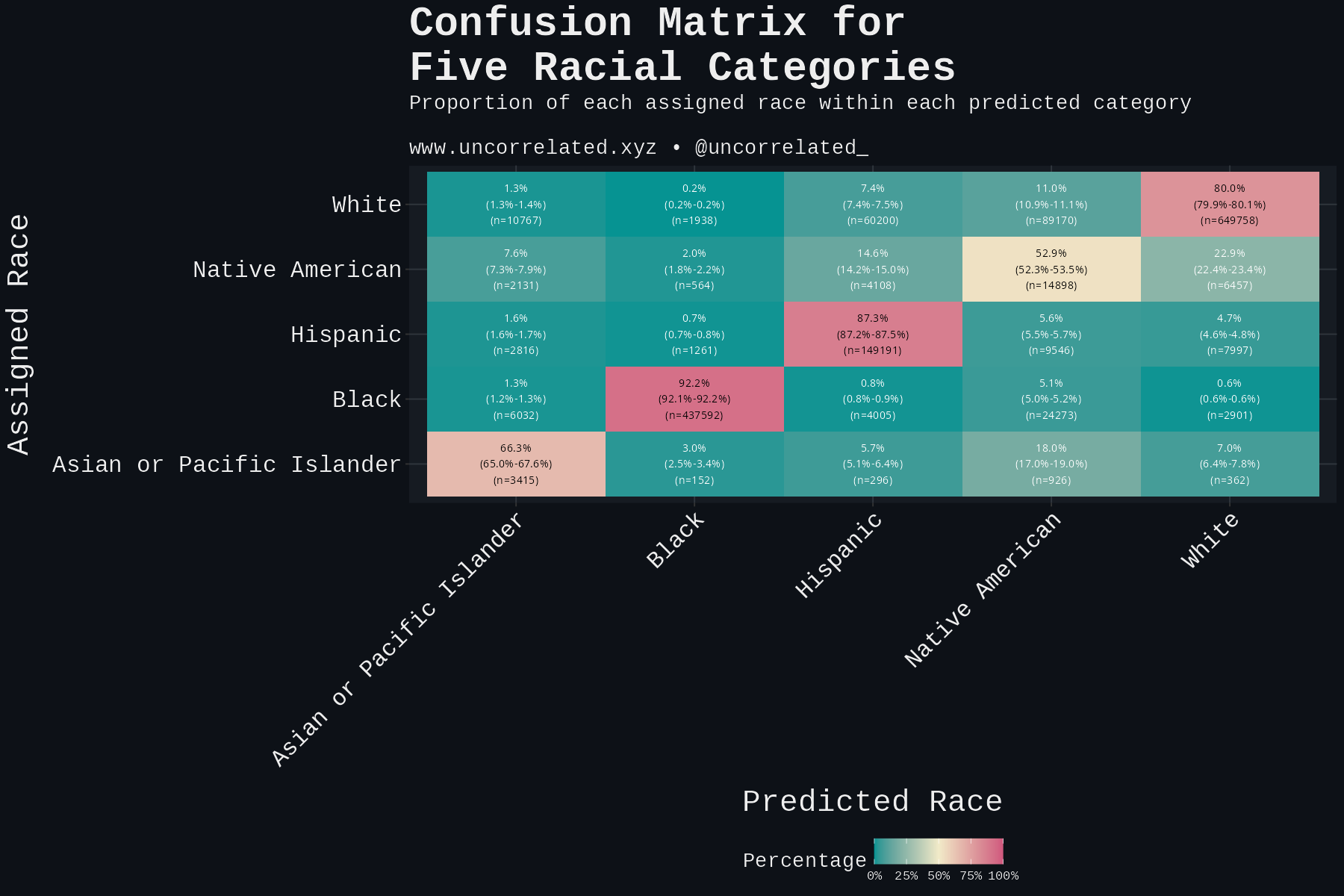
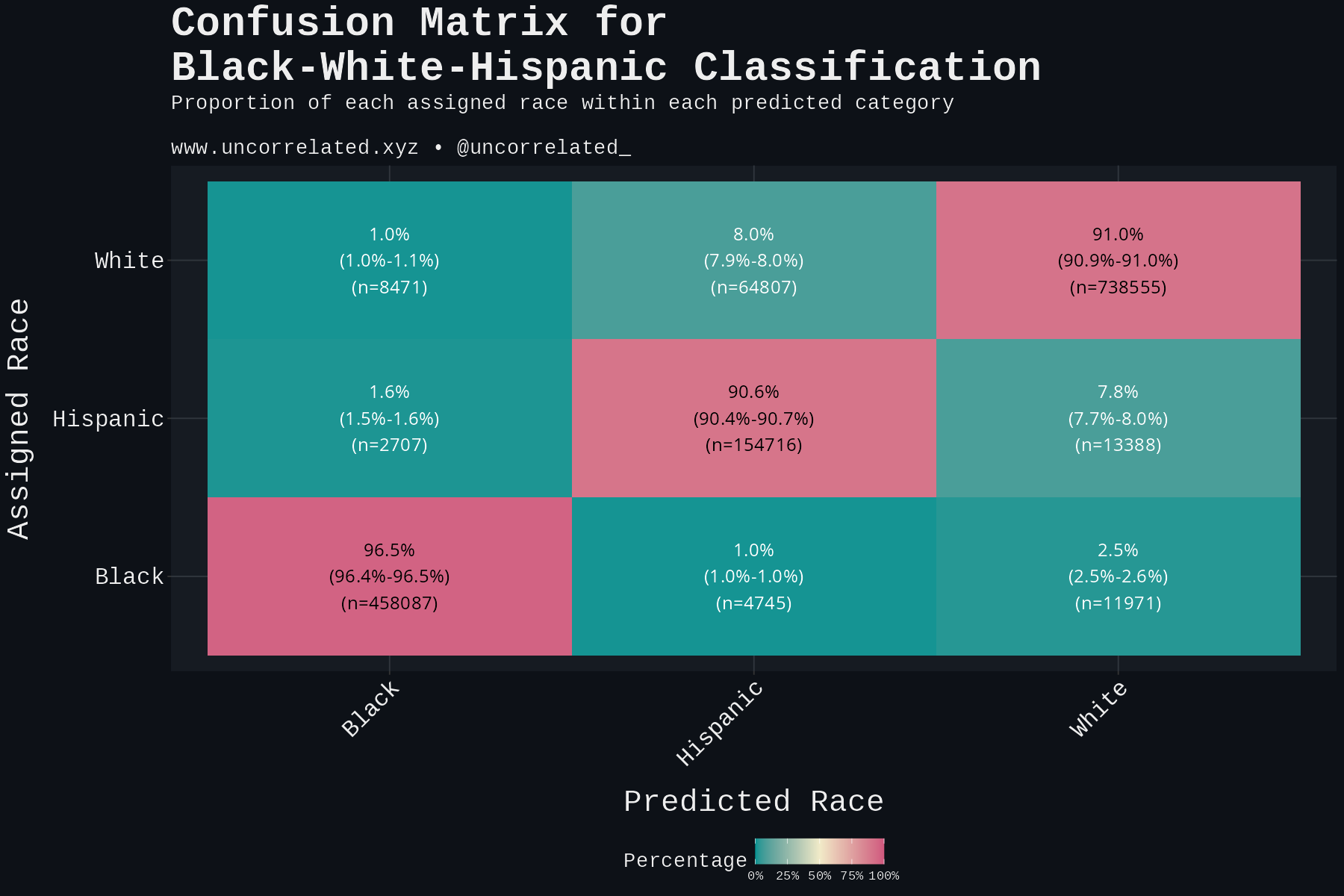
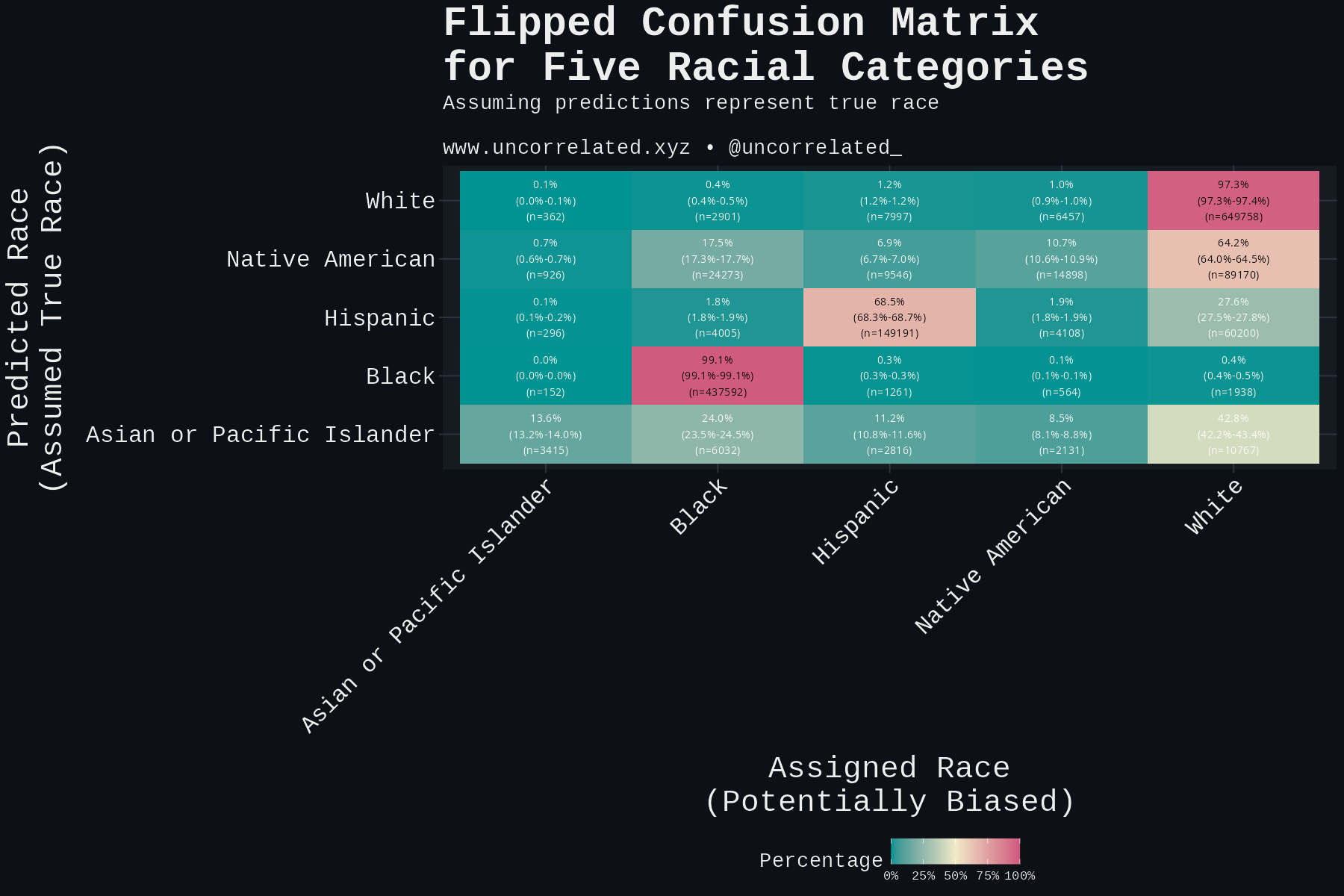
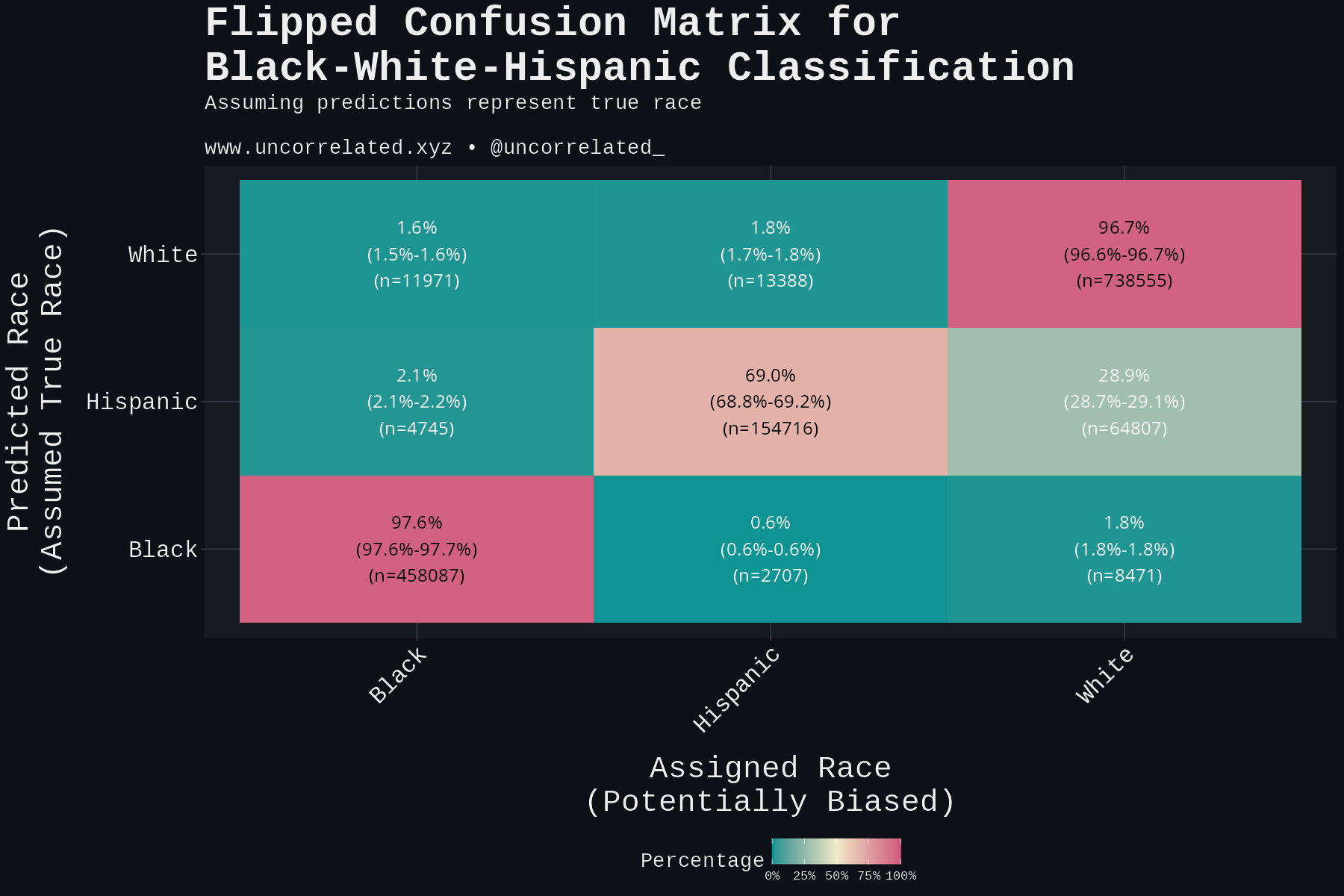
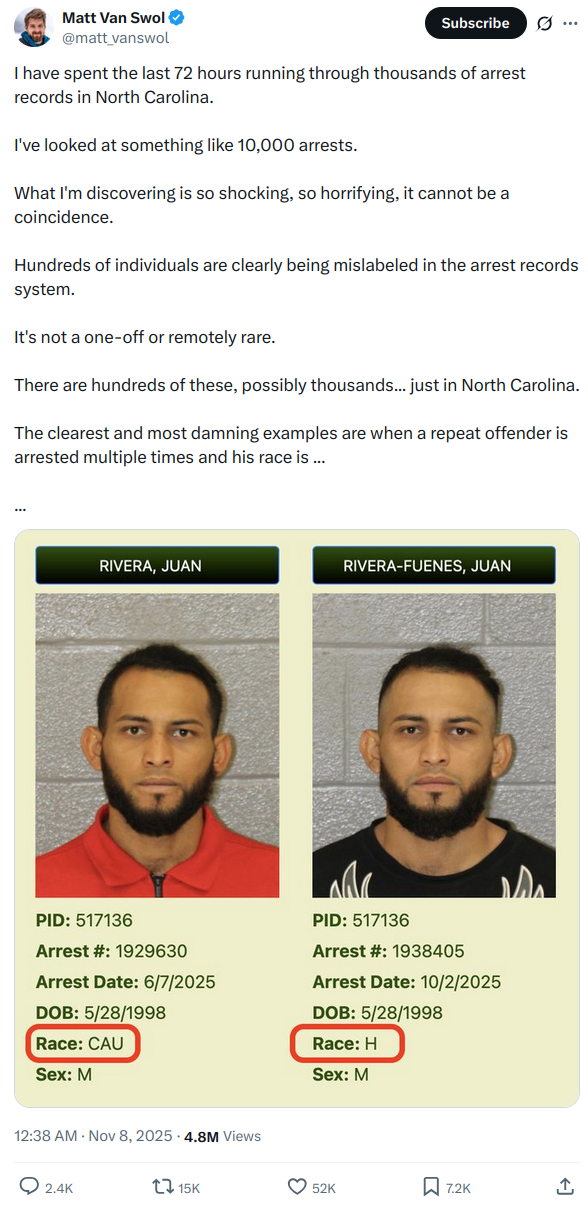
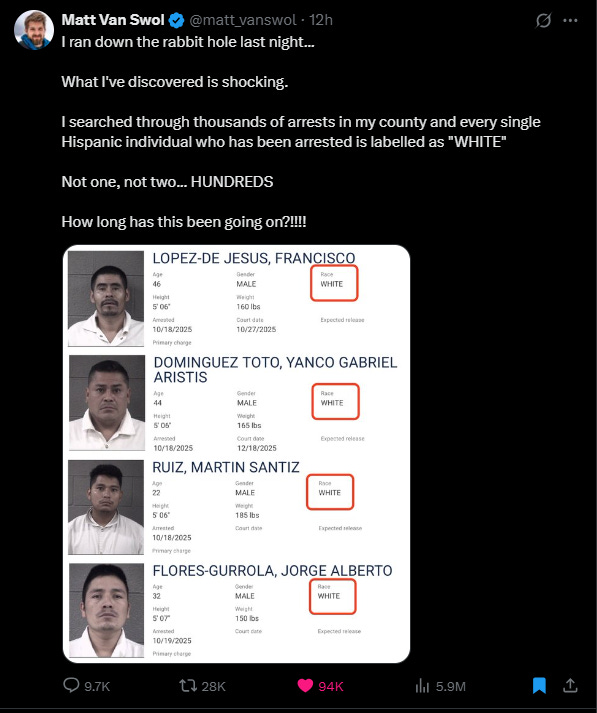
White by Default: Bias in Criminal Racial Assignment
Downloads
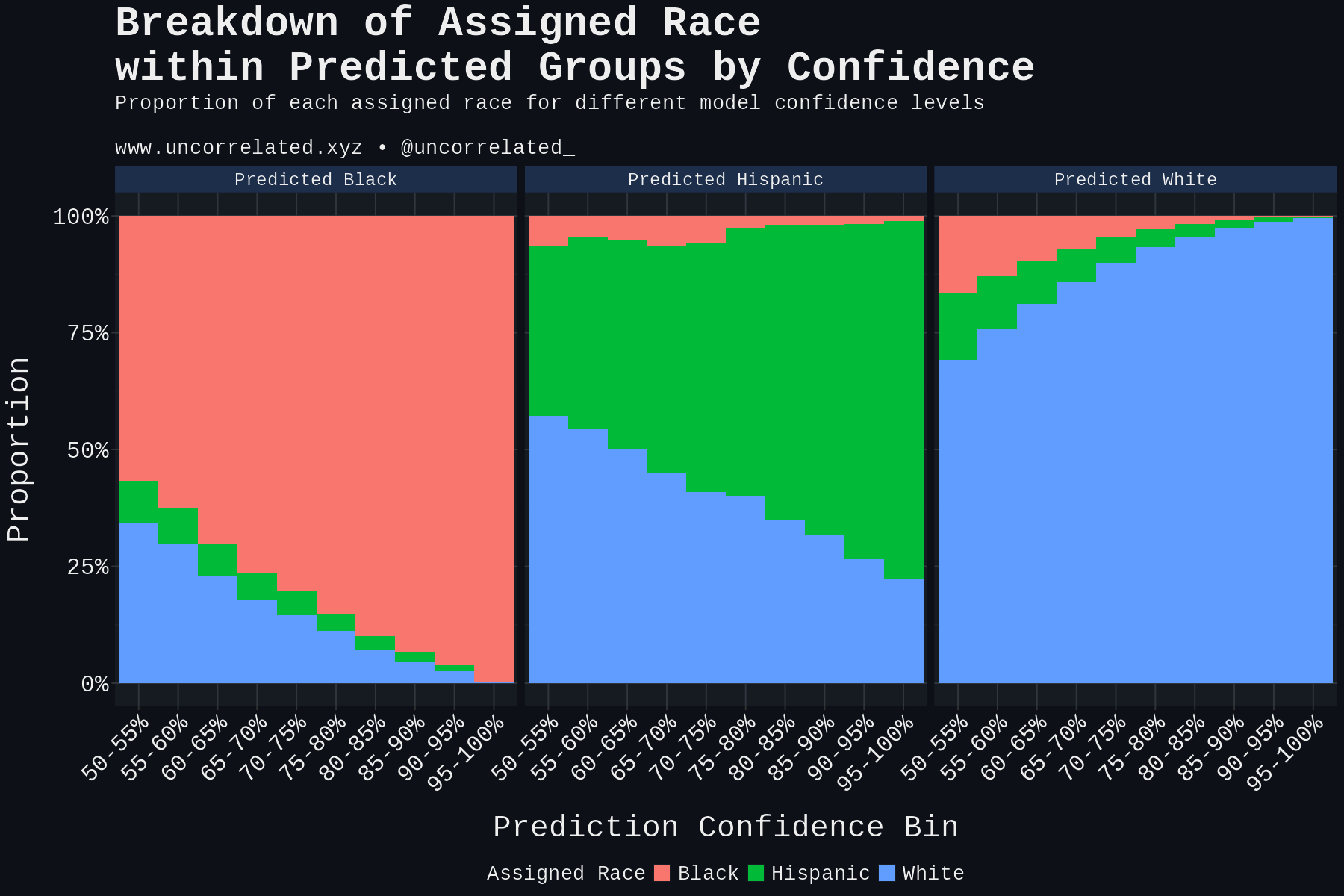
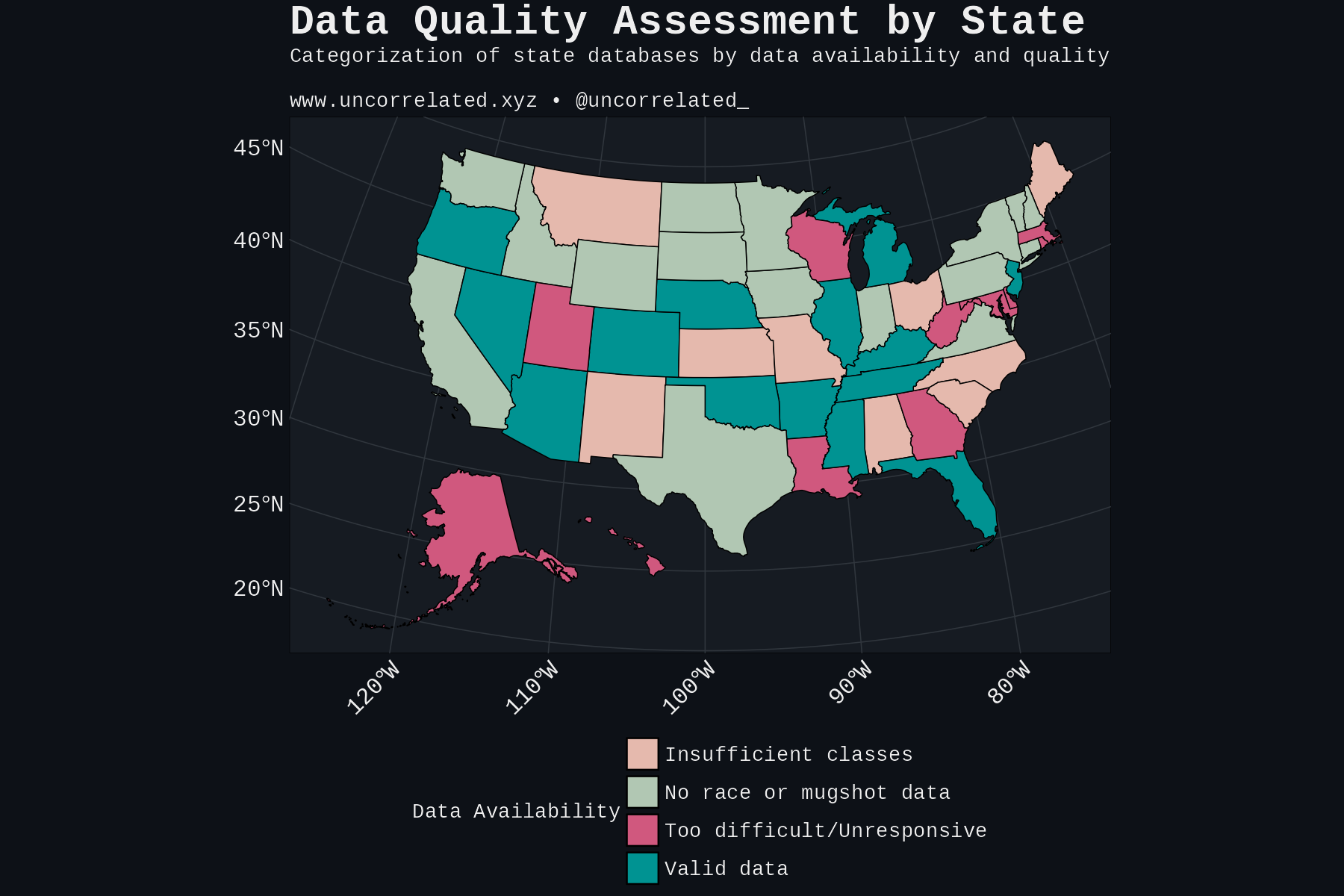
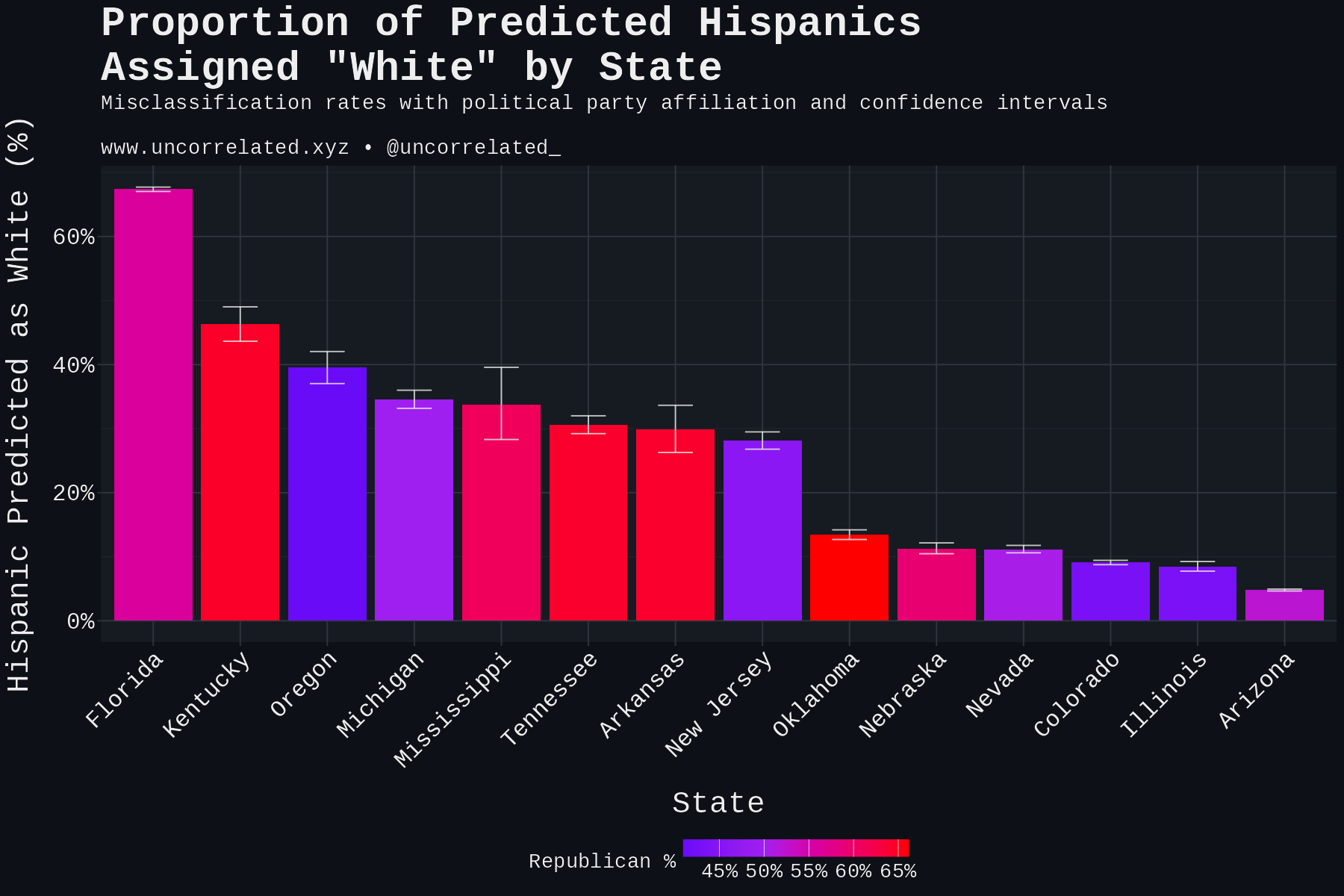
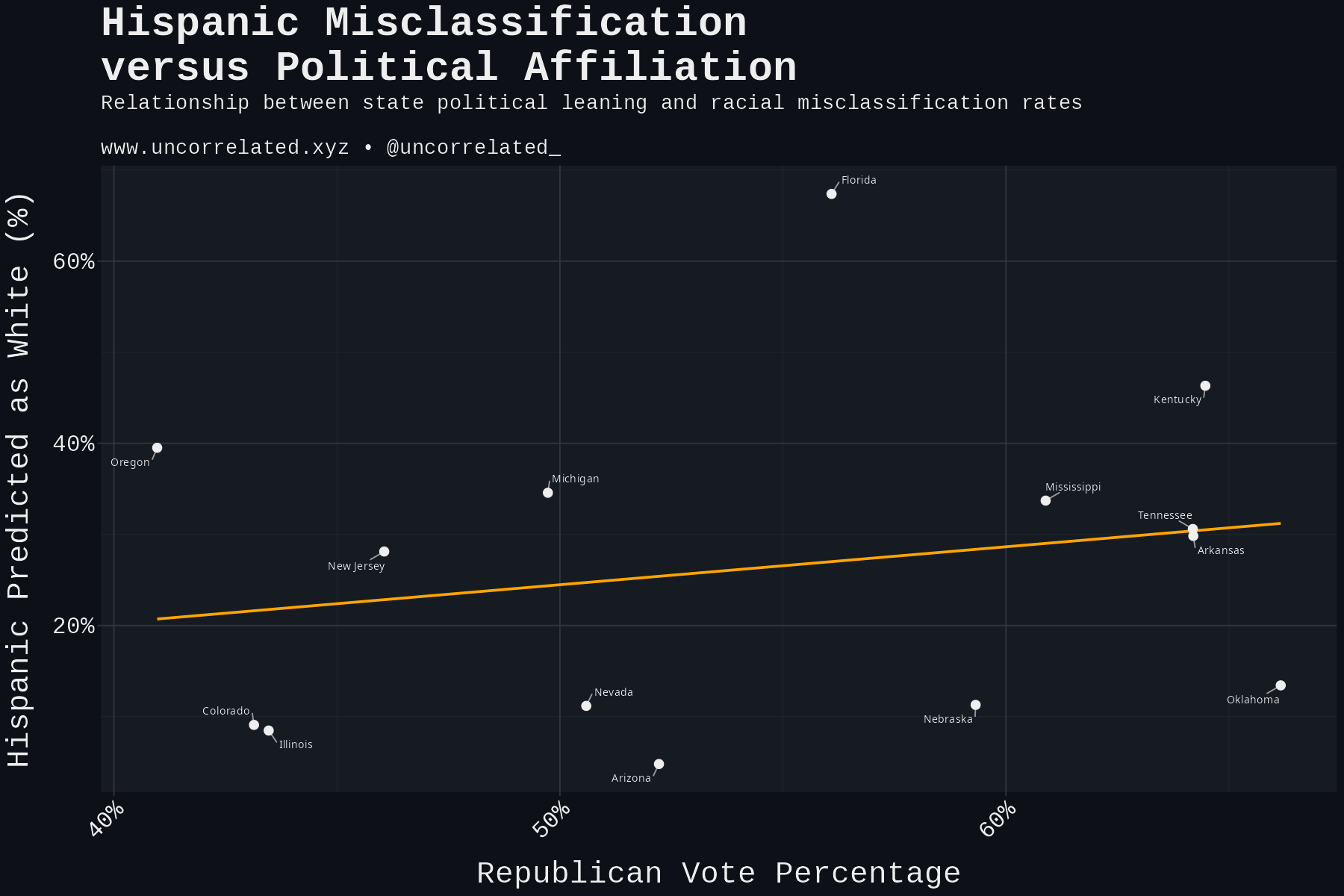
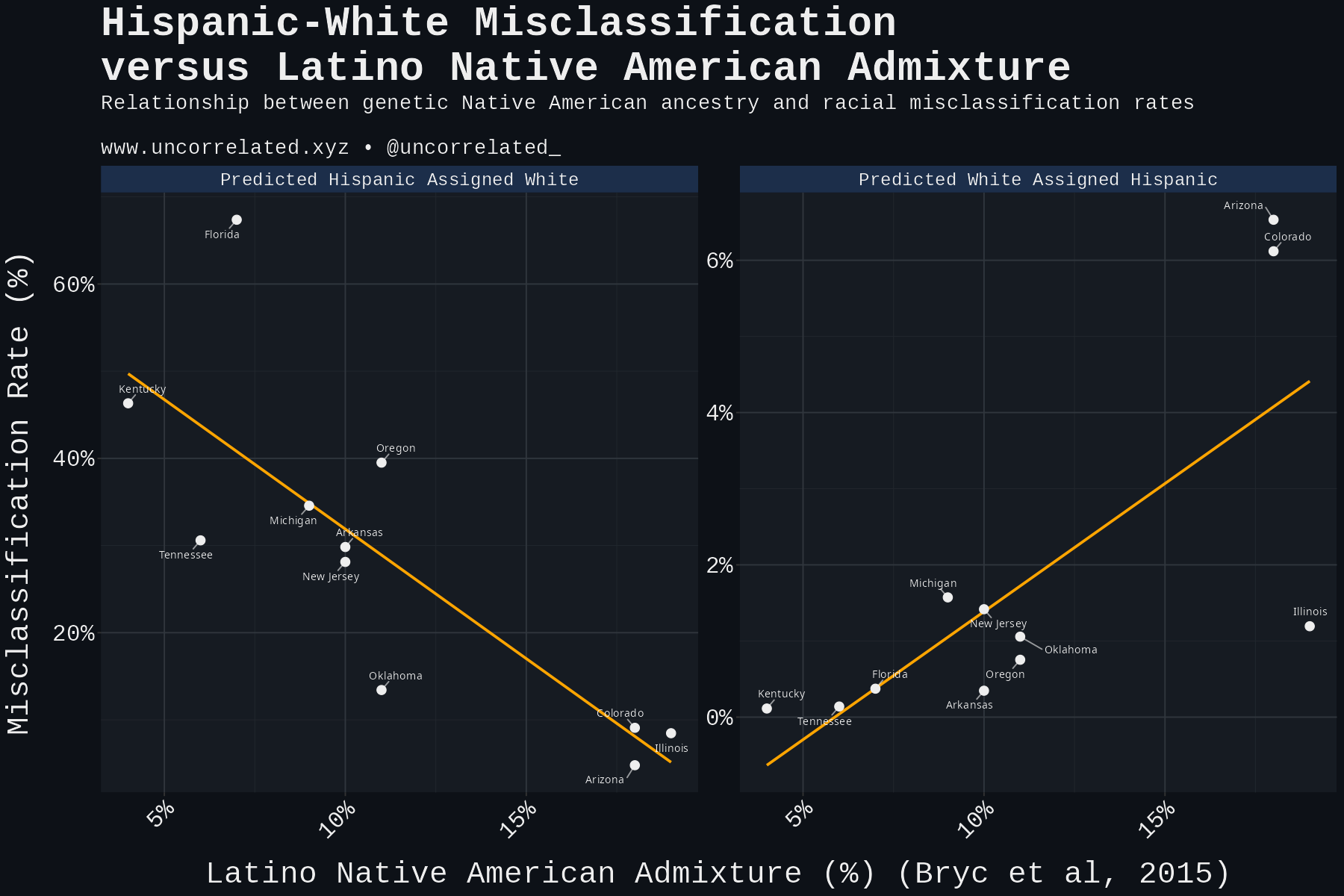
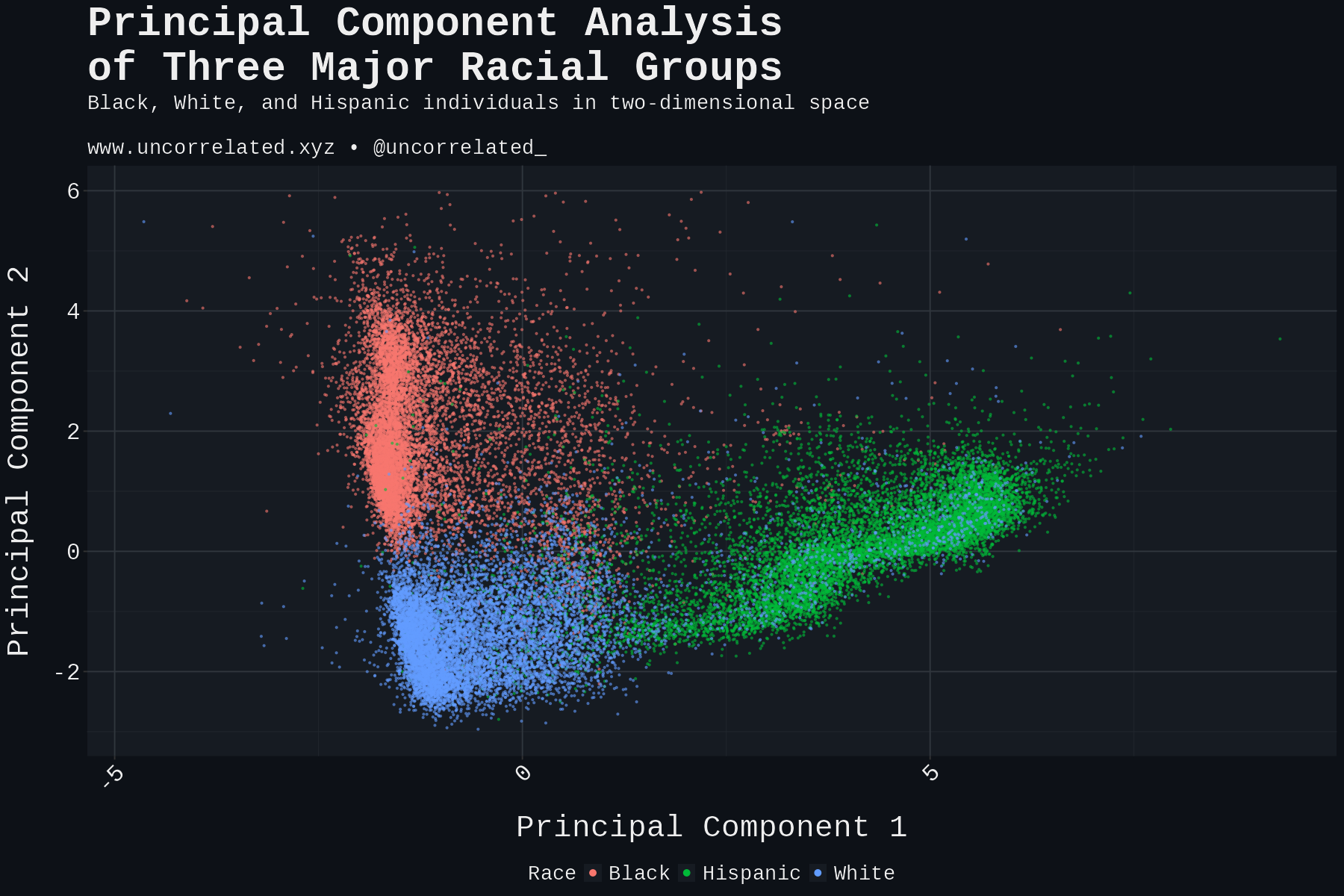
Download Figures31 images
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Appendix
Mathematical Formulation of Bias for Simulation
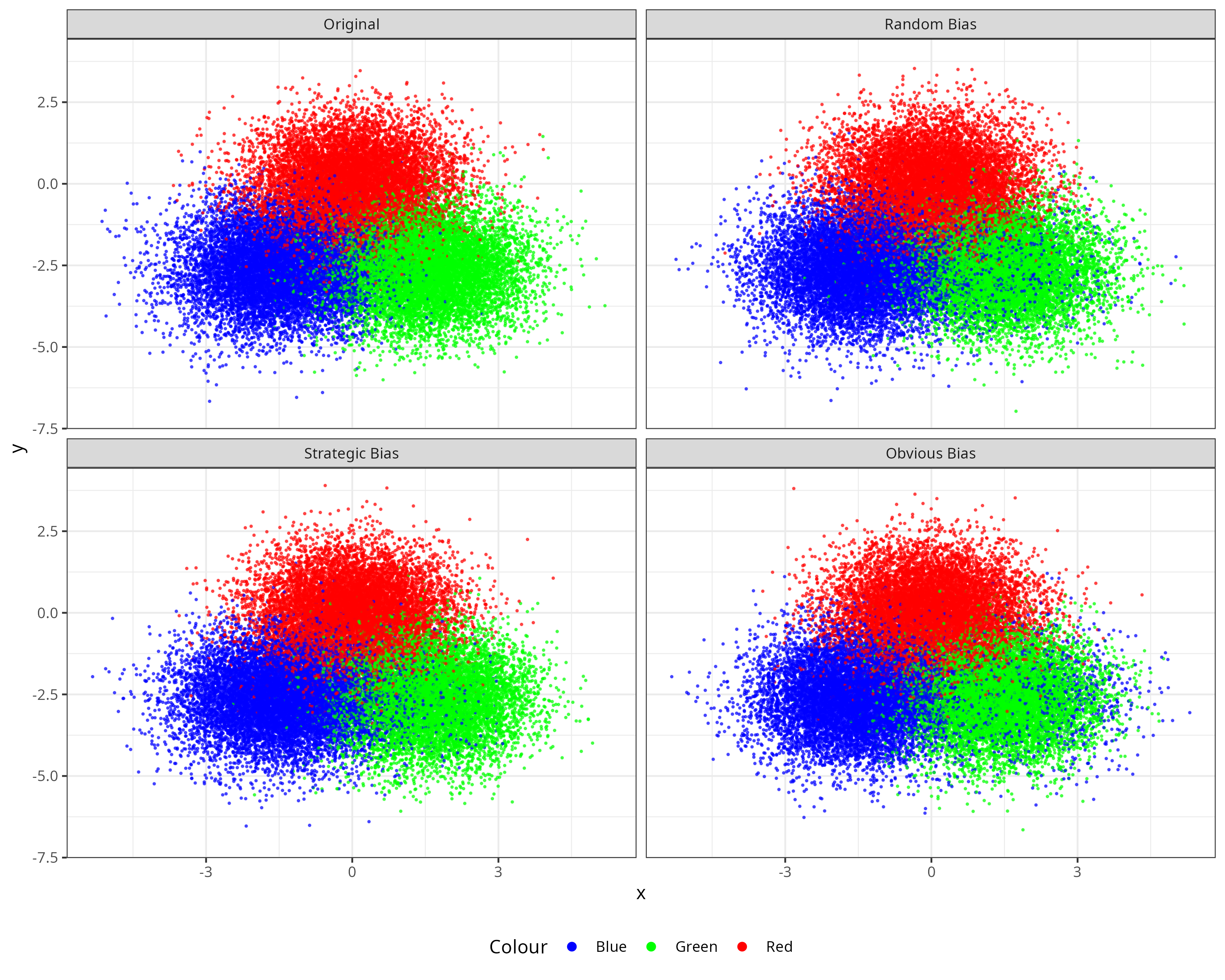
For each bias scenario, we systematically reassigned 10% of Greens to Blue classification, with the selection mechanism varying according to the specific bias type being simulated.
Let the Blue centroid be represented by coordinates in our two-dimensional feature space. For each Green point with coordinates , we calculated the Euclidean distance to the Blue centroid:
The bias assignment probabilities were then defined using exponential functions that create distinct selection patterns for Strategic and Obvious bias types:
These formulations ensure that Strategic bias preferentially selects Green individuals closest to the Blue centroid (higher probability for smaller distances), while Obvious bias preferentially selects those most distant from the Blue centroid (higher probability for larger distances).
We then used weighted sampling on these probabilities (higher values more likely to be sampled) for each respective scenario to produce our end-product simulated datasets:
- Strategic bias: weights proportional to
- Obvious bias: weights proportional to
- Random bias: uniform weights (weights = 1 for all individuals)
Model Training and Evaluation on Simulations
Following bias introduction, we trained multinomial logistic regression models on each simulated dataset using the simple formula race ~ x + y, where x and y represent the two-dimensional coordinates. This straightforward approach mirrors our linear modeling strategy for the real-world data while maintaining interpretive clarity.
To address class imbalances created by the reassignment process, we implemented inverse frequency weighting:
where represents the weight for class , is the total sample size, and is the number of observations in class after bias introduction. This weighting scheme ensures that our models optimize for balanced performance across all three groups. This was done to correct for the imbalance produced by reassignment, and for consistency with the method used on the real dataset.
The simulation process generates four distinct datasets: the original unbiased dataset plus three variants incorporating Random, Strategic, and Obvious bias patterns, respectively. These four scenarios are visualized, illustrating how each bias type creates characteristic distortions in the group assignment patterns.